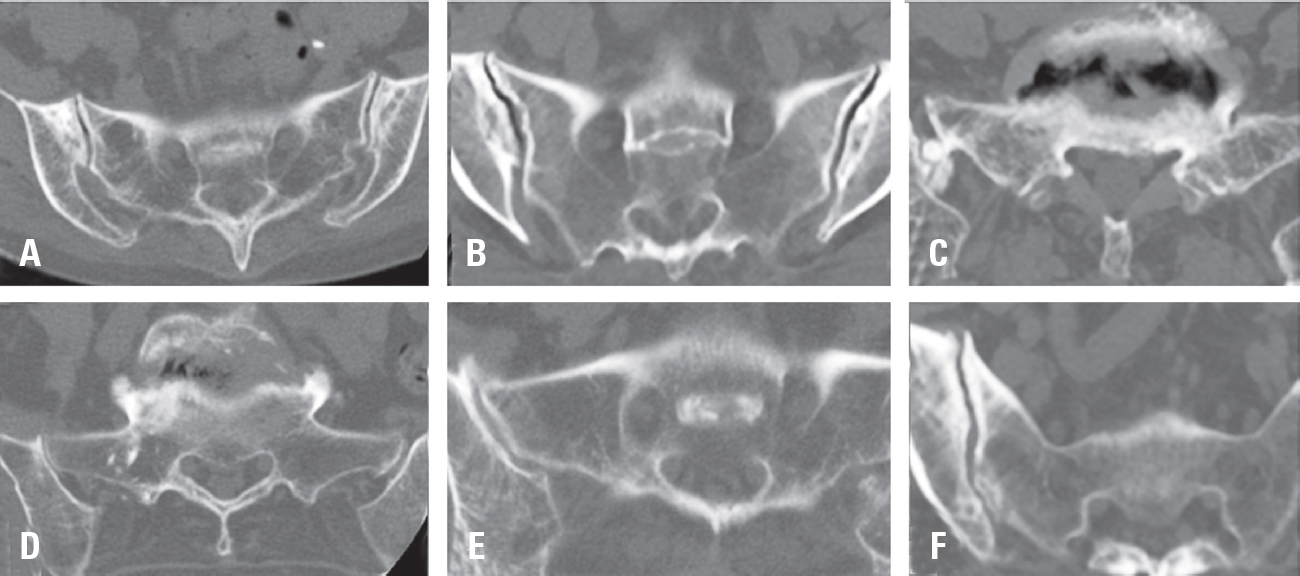
Purpose This study aims to identify risk factors and changes in spino-pelvic parameters associated with Sacroiliac (SI) joint degeneration.
Materials and Methods This multicenter retrospective study included 472 patients who underwent fusion surgery at three hospitals between March 2021 and February 2024. SI joint degeneration was assessed using seven indicators: sclerotic changes, erosion, osteophyte formation, intra-articular bone formation, joint space narrowing, intra-articular gas formation, and subchondral cysts. CT scans were performed preoperatively and 6 months postoperatively. The patients were divided into two groups: those with progression of SI joint degeneration and those without. Standing whole spine lateral X-rays were used to measure a total of 10 spinopelvic parameters both preoperatively and at 6 months postoperatively. Statistical analysis was performed using two-sample t-tests and multivariable logistic regression.
Results Among the 472 patients, 135 (28.6%) showed progression of SI joint degeneration. When comparing the two groups, age (p=0.022), alcohol consumption (p=0.001), smoking (p<0.001), and S1 involvement (p=.04) were associated with SI joint degeneration. Regarding spino-pelvic parameters, patients with SI joint degeneration exhibited significant changes in thoracic kyphosis (p=0.017) and pelvic tilt (p=0.049).
Conclusions Sacrum fixation, smoking, alcohol consumption, and age can be significant risk factors for SIJ degeneration following lumbar fusion surgery.
Purpose This study evaluates the performance of Claude and GPT LLM Vision APIs for automated clinical questionnaire processing in spine surgery by comparing accuracy, efficiency, reproducibility, and cost-effectiveness.
Methods Clinical questionnaires from 56 patients (336 total pages) were processed using a Python 3.12-based system incorporating PDF preprocessing, image enhancement via OpenCV, and direct LLM Vision analysis. Both models were evaluated on 26 questionnaire items (1,456 data points) using accuracy comparison, processing time measurement, token utilization analysis, and intra-class correlation coefficient (ICC) assessment through three independent iterations.
Results GPT achieved 98.83% accuracy (1,439/1,456) compared to Claude's 97.94% (1,426/1,456). Both models processed questionnaires in 27 seconds per set, representing 68% time reduction versus manual entry (85 seconds). GPT demonstrated 59% cost advantage ($0.023 vs. $0.056 per questionnaire), while Claude showed superior reproducibility (ICC 0.98 vs. 0.96). GPT achieved 100% accuracy across 21 items versus Claude's 17 items. Error analysis identified predominantly handwriting recognition (52%) and image quality issues (28%), with 89% of errors successfully flagged for review.
Conclusions Both models achieve clinical-grade performance exceeding 90% accuracy. GPT demonstrates superior accuracy and cost-effectiveness, while Claude provides better reproducibility. Model selection should be guided by institutional priorities regarding accuracy, reproducibility, and operational scale.


 First
First Prev
Prev